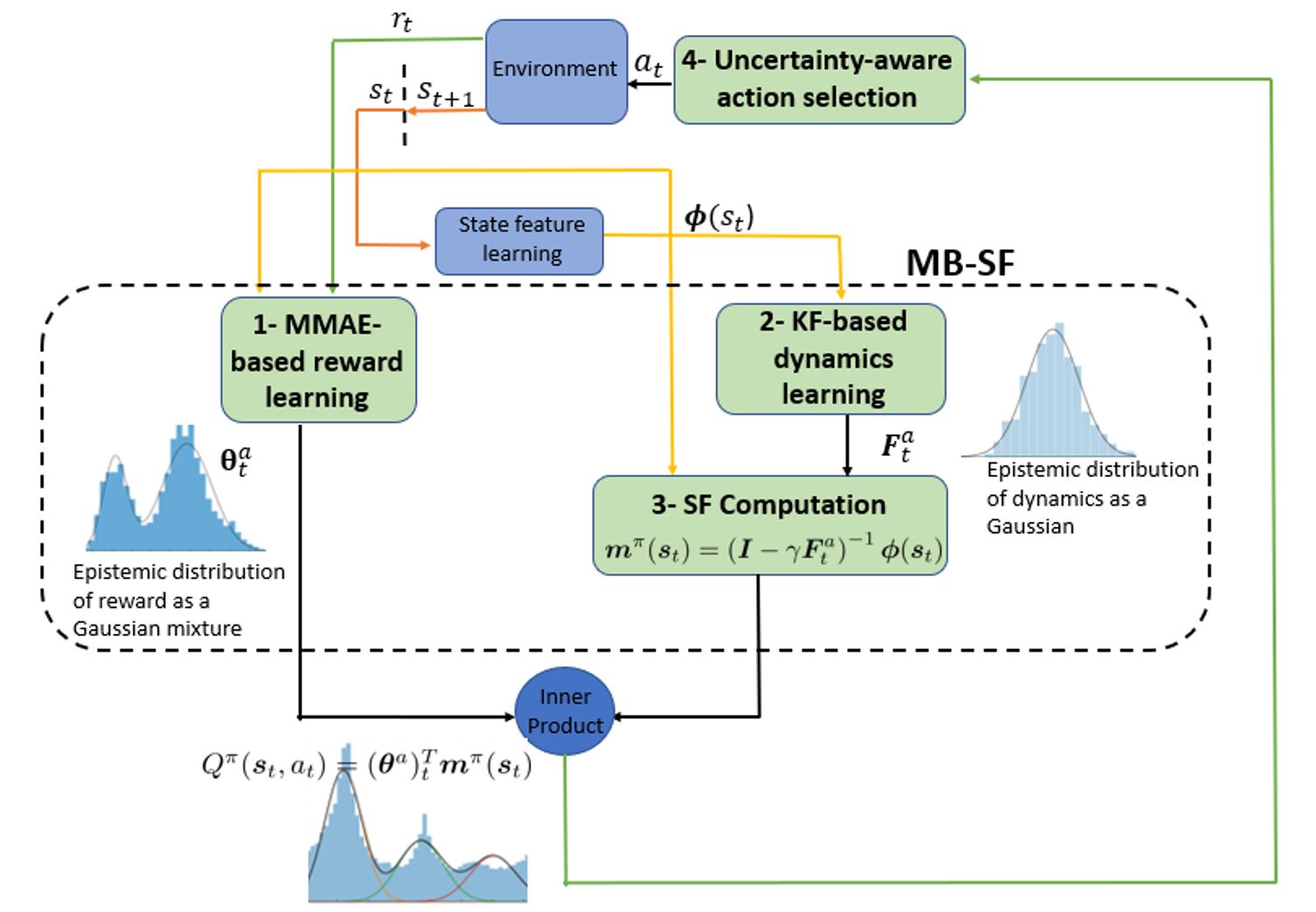
The ability to transfer and generalize knowledge gained from previous experiences to downstream tasks can significantly improve sample efficiency of reinforcement learning (RL) algorithms. Recent research indicates that successor feature (SF) RL algorithms enable knowledge generalization between tasks with different rewards but identical transition dynamics. Furthermore, uncertainty-aware exploration is widely recognized as another appealing approach for improving sample efficiency.
Putting together two ideas of hybrid model-based successor feature (MB-SF) and uncertainty leads to an approach to the problem of sample efficient uncertainty-aware knowledge transfer across tasks with different transition dynamics or/and reward functions. In this paper, the uncertainty of the value of each action is approximated by a Kalman filter (KF)-based multiple-model adaptive estimation, which treats the parameters of a model as random variables. To the best of our knowledge, this is the first attempt at formulating a hybrid MB-SF algorithm capable of generalizing knowledge across large or continuous state space tasks with various transition dynamics while requiring less computation at decision time than MB methods.
We highlight why previous SF-based methods are constrained to knowledge generalization across same transition dynamics, and design a set of demonstration tasks to empirically validate the effectiveness of our proposed approach. The results show that our algorithm generalizes its knowledge across different transition dynamics, and outperforms existing SF and MB approaches. We believe that our proposed framework can account for the computationally efficient behavioural flexibilities observed in the empirical literature and can also serve as a solid theoretical foundation for future experimental work.
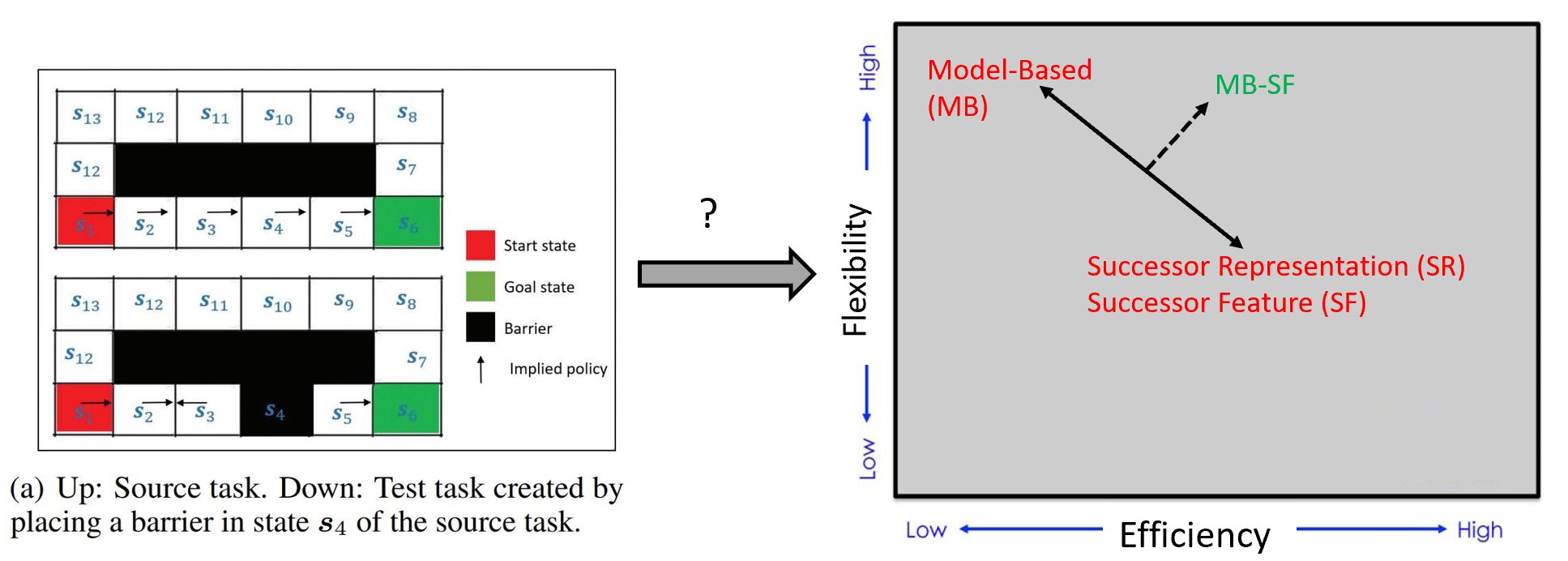
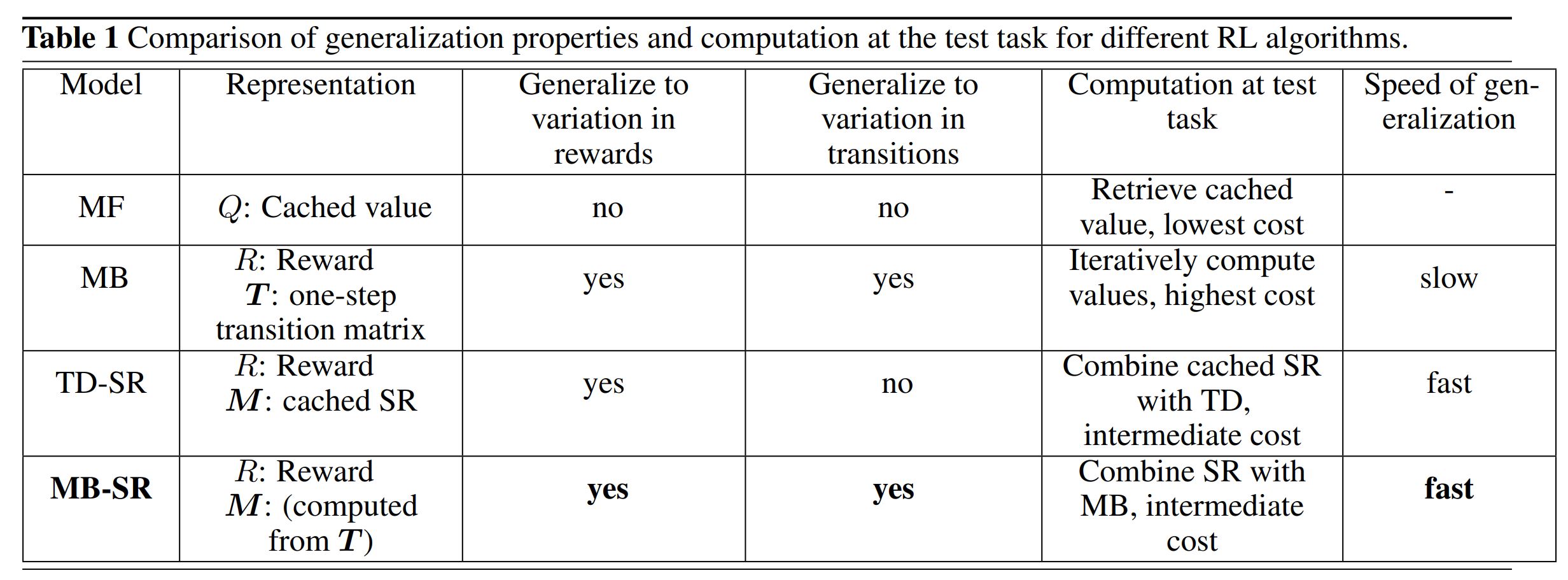
Table 1 summarizes the generalization properties and computation required at test tasks for various RL algorithms.
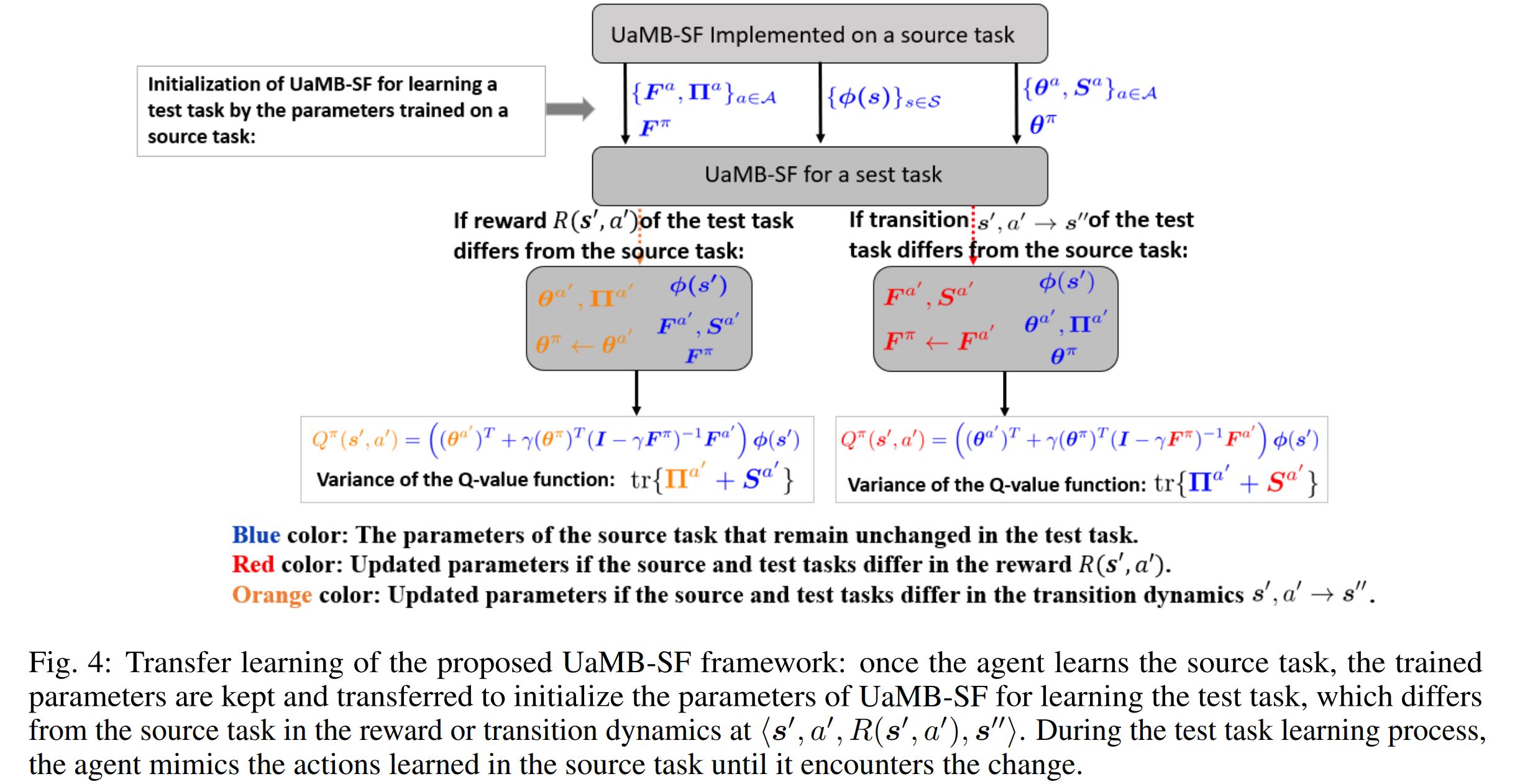
The transfer setup of the proposed UaMB-SF algorithm is presented in Fig. 4. θa and F a capture changes in the reward function and transition dynamics, respectively. After training UaMB-SF on a source task, only a few samples are needed to update θa and F a , eliminating the need for exhaustive interactions from scratch.
@article{malekzadeh2023uncertainty,
title={Uncertainty-aware transfer across tasks using hybrid model-based successor feature reinforcement learning☆},
author={Malekzadeh, Parvin and Hou, Ming and Plataniotis, Konstantinos N},
journal={Neurocomputing},
volume={530},
pages={165--187},
year={2023},
publisher={Elsevier}
}